
TLDR
Choosing between NVIDIA RTX, Tesla, and Jetson Orin for edge inference comes down to three trade-offs: thermal budget, model size, and deployment footprint. RTX workstation cards inside a Nuvo-10108GC or Nuvo-10208GC handle multi-stream video analytics at 350W. Jetson Orin platforms like the NRU-220 run vision and LLM workloads in 25-60W with zero fans. Tesla/datacenter cards sit in between but rarely make sense at the edge anymore. Match the GPU to your power envelope first — the model will follow.
Related reading: how the NRU-220 brings Jetson Orin perception to airport ramp vehicles.
For the deploy-and-update side of an edge build, see our guide to the AI model lifecycle at the edge.
Overview
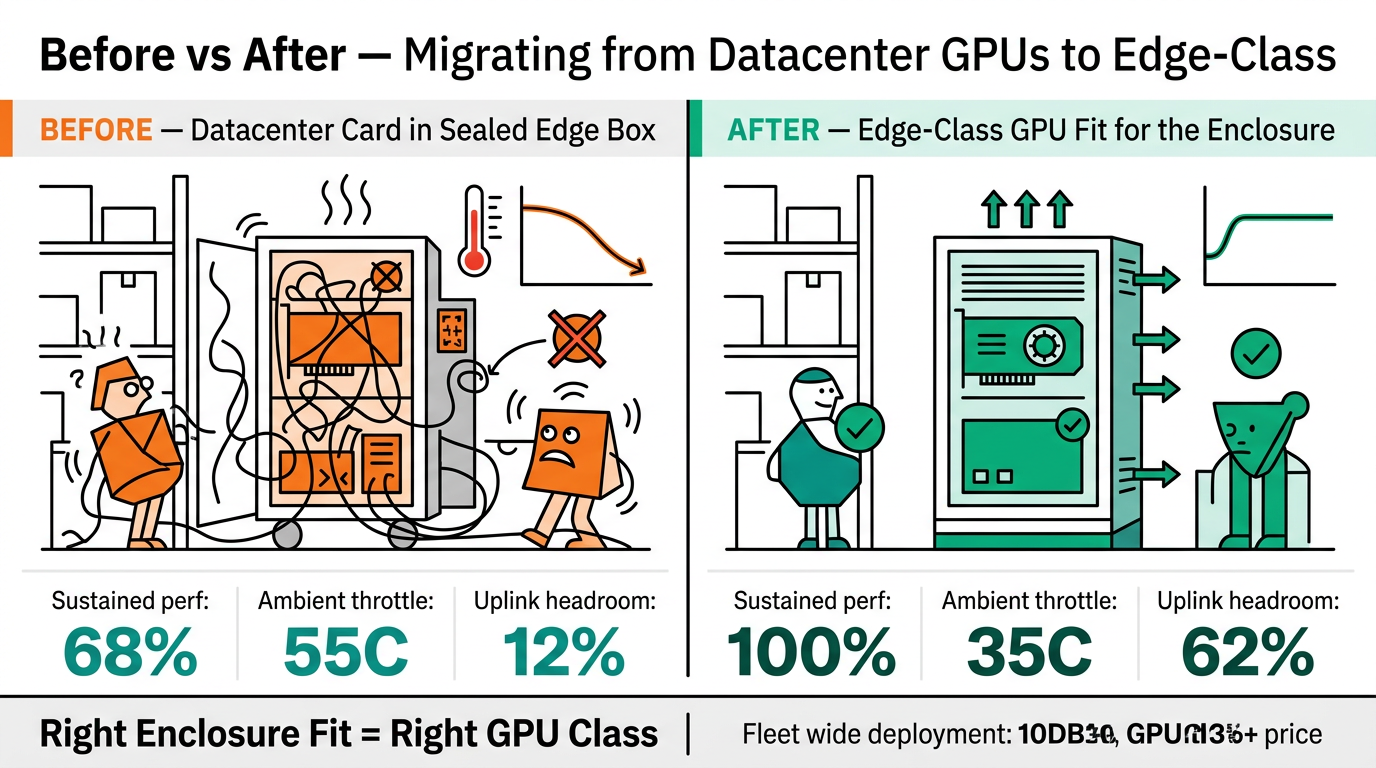
Most engineers still ask "which GPU is fastest?" when they should be asking "which GPU survives my enclosure?" Edge inference isn't a benchmark exercise. It's thermal engineering wrapped around a machine-learning problem. An RTX 4000 Ada rated for 130W can't run in a sealed NEMA cabinet at 50°C without active cooling. A Jetson Orin NX can. That single fact drives more deployment decisions than any MLPerf chart.
This comparison covers three GPU classes for edge inference — NVIDIA RTX professional cards, legacy Tesla (now datacenter-class), and Jetson Orin embedded modules — mapped against the Neousys platforms that host them. For a broader platform comparison, see our guide on Intel vs AMD vs Jetson edge AI platform selection. If you're designing a vision pipeline end-to-end, the machine vision system design guide walks through camera-to-inference latency budgets. And for a real-world RTX deployment case, review how Nuvo-10108GC cut warehouse AMR collision rates by 91%.

Head-to-Head Comparison
| Parameter | RTX 4000/5000 Ada | Tesla T4 / L4 (datacenter) | Jetson Orin NX/AGX |
|---|---|---|---|
| TDP range | 130-350W | 70-150W | 15-60W |
| Form factor | Dual-slot PCIe card | Low-profile PCIe card | SOM on carrier board |
| FP16 throughput | 165-660 TFLOPS | 65-242 TFLOPS | 70-275 TOPS (INT8) |
| Video decode | 8-16 streams 4K | 8 streams 4K | 4-8 streams 4K |
| Host platform | Nuvo-10108GC, Nuvo-10208GC | Nuvo-10108GC (L4) | NRU-220 |
| Cooling | Active fans + airflow | Active fans | Fanless conduction |
| Operating temp | 0-50°C (host-limited) | 0-45°C | -25 to 70°C |
| Typical price | $1,500-8,000 | $2,000-10,000 | $500-2,500 |
Use Case Mapping
Different GPU classes earn their keep in different deployments. The table below maps common edge workloads to the right hardware.
| Workload | Best fit | Why | Platform |
|---|---|---|---|
| 16-camera factory QA | RTX 4000/5000 Ada | High decode count + high FP16 | Nuvo-10208GC (dual RTX) |
| Autonomous mobile robot (3 cams + LiDAR) | Jetson Orin AGX | Power budget + fanless | NRU-220 |
| Single-line defect detection | RTX 4000 Ada | Deterministic latency, upgrade path | Nuvo-10108GC |
| Perimeter surveillance (8 streams) | L4 or RTX 4000 Ada | Balanced throughput/TDP | Nuvo-10108GC |
| In-cabin driver monitoring | Jetson Orin NX | Sub-25W, automotive power | NRU-220 |
| Outdoor/NEMA 4X enclosure | Jetson Orin | Fanless, wide-temp | NRU-220 |
| Hazardous-location edge node | Jetson Orin | No moving parts | NRU-220 |
Workload density is the honest filter. If you're decoding four or more concurrent 4K streams and running a transformer-based detector, the math favors RTX. If you're shipping a rolling enclosure that gets dusty, vibrates, and never sees a technician, Jetson Orin wins on mean-time-between-failure.

Migration Considerations
Teams moving from Tesla T4/V100 datacenter cards to edge-class GPUs usually hit three surprises. First, TensorRT engines are GPU-specific: a model compiled for Tesla L4 won't run on Jetson Orin without recompilation, and vice versa. Budget two engineering weeks for INT8 calibration and accuracy validation. For GPU selection specifically tuned to food-processing QA, our earlier comparison of Nuvo-9160GC vs Nuvo-10108GC covers this trade-off.
Second, thermal derating. A Tesla L4 tested at 25°C ambient will throttle inside a sealed edge box at 45°C. The Nuvo-10108GC handles this with engineered airflow and a 60°C spec, but you still need to model the customer's cabinet — not just the chassis.
Third, the model zoo shrinks. Jetson runs a subset of ops cleanly; anything exotic (custom CUDA kernels, recent attention variants) may need a rewrite. If your team isn't comfortable with TensorRT plugin authoring, stay on RTX for now and revisit Jetson when Orin Thor matures.
Networking is the silent killer. A 16-camera GPU workload pulls 400-800 Mbps sustained; feeding that into a gigabit uplink creates buffer bloat that masquerades as GPU latency. Pair edge GPUs with 10G-capable switching — the PLANET IXT-705AT is a common pick for retrofit sites.
Conclusion
Pick the GPU that fits your enclosure, not your benchmark spreadsheet. RTX Ada inside a Nuvo-10208GC is the right call for dense video analytics at factory scale. Jetson Orin in an NRU-220 is the right call for vehicles, outdoor enclosures, and anywhere a fan is a warranty claim waiting to happen. Tesla-class cards still have a niche in compact datacenter edge nodes, but for most industrial deployments in 2026 they've been squeezed out by RTX below and Jetson above.
Follow Neteon on LinkedIn for deployment breakdowns. Contact [email protected] or visit www.neteon.net for datasheets and configuration support.
Related Products




FAQs
Which NVIDIA GPU is best for edge AI inference in 2026?
It depends on your thermal envelope. For 16+ camera analytics in factory settings, RTX 4000/5000 Ada inside a Nuvo-10108GC or Nuvo-10208GC delivers the highest throughput. For vehicle-mounted, outdoor, or fanless deployments, Jetson Orin NX/AGX inside an NRU-220 wins on power efficiency and reliability. There is no single best GPU — only the best GPU for your enclosure and power budget.
Is NVIDIA Tesla still relevant for edge deployments?
Not really. Tesla T4 and L4 datacenter cards are being squeezed out at the edge: RTX Ada covers the high-performance tier with better video decode, and Jetson Orin covers the low-power tier with a fanless design. Tesla-class cards still appear in compact datacenter-edge nodes and hybrid deployments, but for industrial edge AI in 2026 most new designs go to RTX or Jetson.
Can I run the same TensorRT model on RTX and Jetson Orin?
No. TensorRT engines are compiled to a specific GPU architecture. A model optimized for RTX Ada will not load on Jetson Orin, and vice versa. Plan for two to three weeks of INT8 calibration and accuracy validation per target platform. Jetson also runs a subset of custom CUDA ops, so exotic kernels may need rewriting.
How do I choose between Nuvo-10108GC and Nuvo-10208GC?
The Nuvo-10108GC supports a single 350W RTX GPU and fits single-line inspection or 8-stream surveillance workloads. The Nuvo-10208GC supports dual 350W GPUs for 16+ camera analytics or multi-model inference. Pick single-GPU unless your workload already saturates one card — otherwise you are paying for idle silicon.
What networking do I need for GPU edge inference?
For multi-camera workloads, plan for 10G uplinks. A 16-camera 4K stream can sustain 400-800 Mbps, and gigabit switches introduce buffer bloat that looks like GPU latency. Industrial 10G media converters like the PLANET IXT-705AT are common retrofit choices where fiber already exists. Pair GPU nodes with managed switches supporting VLAN isolation and QoS.


