
TLDR
Training a model is the short part of the job. Keeping it accurate across a fleet of edge nodes for three years is the long part. This guide builds a working model lifecycle on industrial hardware: containerized deployment, drift monitoring, and staged over-the-air updates, using the Nuvo-10208GC, the NRU-220, and a managed OT network you control.
For the fleet-scale view of this, including site aggregators and unattended rollback, see our guide to remote management of edge AI fleets.
Related reading: see our guide to building an edge-to-cloud data pipeline from sensor to dashboard.
Overview
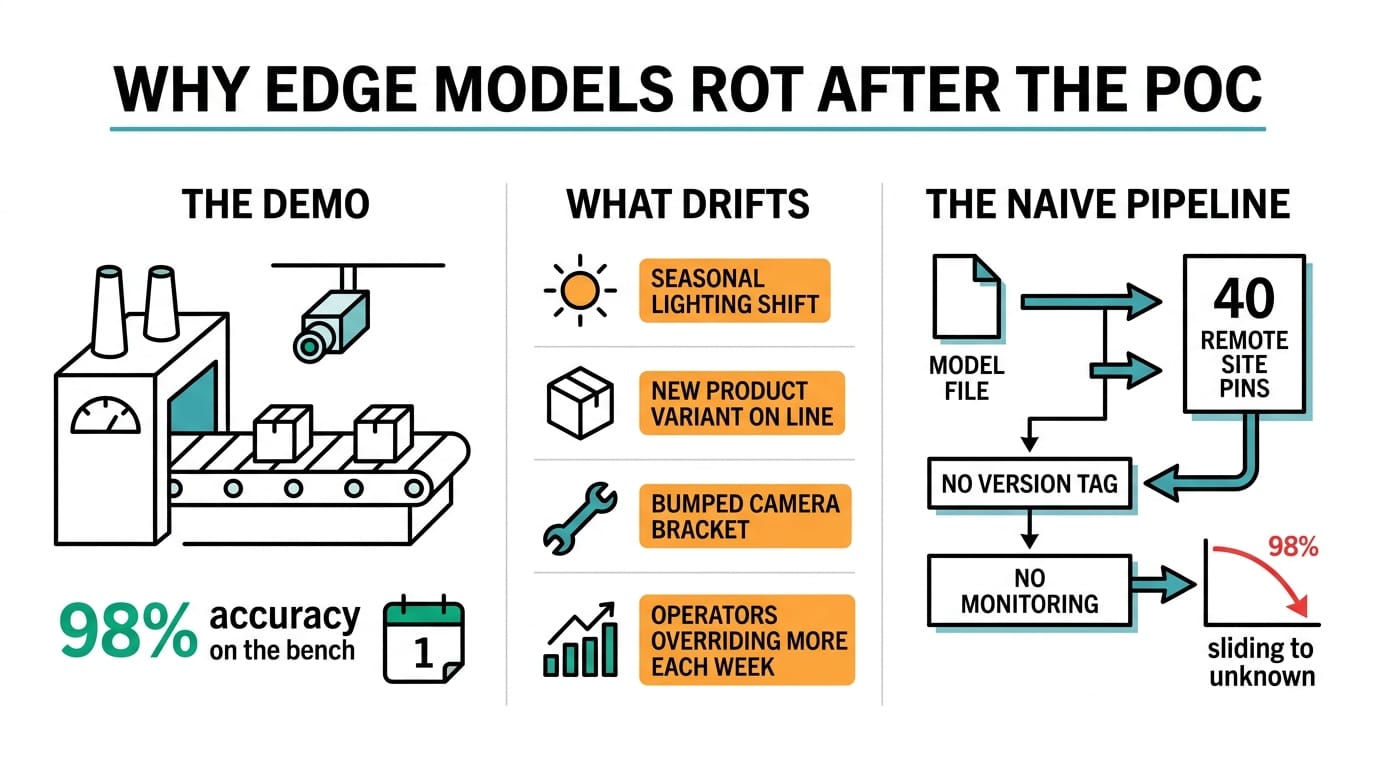
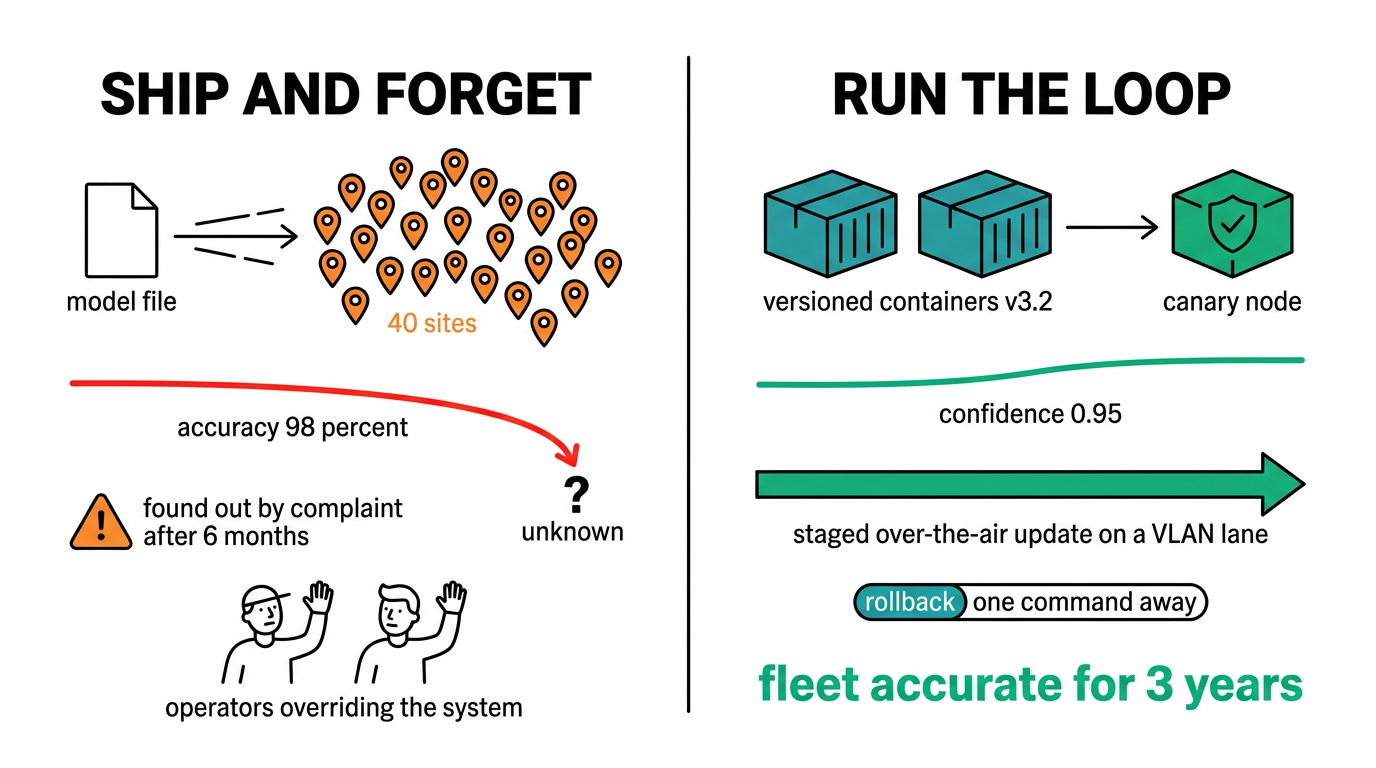
Most edge AI projects stall right after the proof of concept. The demo model hits 98% on the bench, ships to forty sites, and six months later nobody can say whether it still works. Lighting shifts with the seasons. A new product variant shows up on the line. Someone bumps a camera bracket during maintenance. Accuracy slides, and the only outward sign is operators overriding the system a little more each week.
The cure is to treat the model like deployed software. Version it, watch it in production, and push updates on a schedule you set rather than waiting for a complaint. We compared the inference hardware in our guide to GPU computing for edge inference, and laid out the plumbing in how to design a converged IT/OT network. This piece sits between those two: the deploy, monitor, update loop. If you are also pulling field telemetry, our remote monitoring stack walkthrough pairs with it directly.
Components needed
| Role | Hardware | Why it is here |
|---|---|---|
| Vision inference node | Nuvo-10208GC | RTX-class GPU for multi-camera, high-resolution models |
| Compact inference node | NRU-220 | Jetson Orin, fanless, fits low-power or space-tight sites |
| Management host | Nuvo-11531 | Runs the registry, dashboards, and update orchestration |
| OT network | PLANET IGS-20160HPT | Managed L2 switch with PoE, segments update traffic from control traffic |
| Software | Container runtime, model registry, MQTT broker | Open-source stack, no per-node license |
The split between a GPU box and a Jetson box is deliberate. Heavy models run on the Nuvo-10208GC; lighter detectors run on the NRU-220 where power and space are tight. Both pull the same container images, so one build feeds the whole fleet.
Step-by-step setup
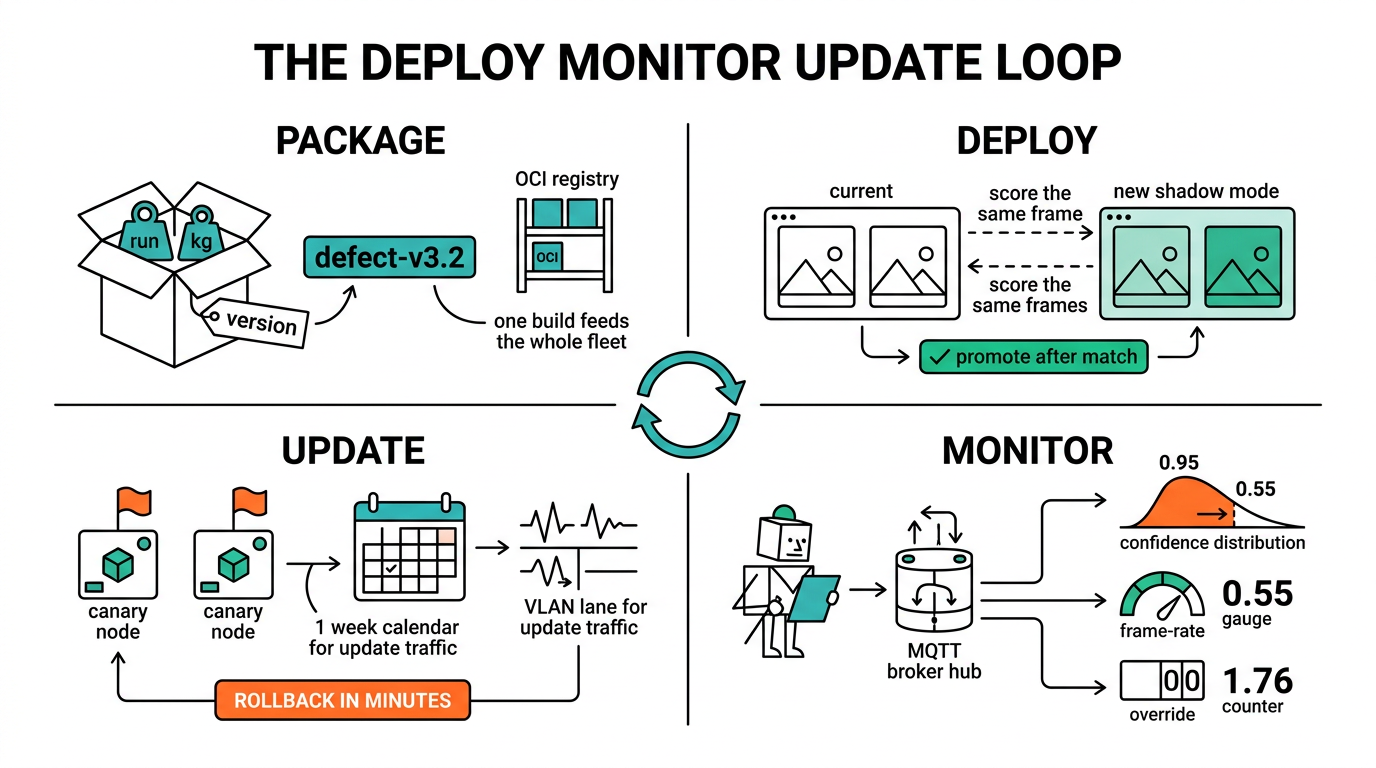
Package the model as a container with its runtime, weights, and a version tag baked into the image name. Never ship a bare model file to a node. You lose track of what is running where inside a month.
Stand up a registry on the Nuvo-11531. Any OCI registry works. Each node pulls by tag, so defect-v3.2 means the same thing on every box.
Deploy to one node first. Run the new version next to the current one in shadow mode, scoring the same frames without acting on the output. Compare the two for a shift, then promote.
Wire telemetry last. Each node publishes confidence scores, frame rates, and override counts to the MQTT broker. That feed is what tells you a model is drifting before a plant manager does.
Configuration
Log the confidence distribution, not just the final label. A model that still picks the right class but does it at 0.55 instead of 0.95 is on its way out, and the label alone hides that.
Tag one or two nodes as canaries. New versions land there first and sit for a week of real shifts before the rest of the fleet pulls them. On the PLANET IGS-20160HPT, put update traffic on its own VLAN so a multi-gigabyte image pull never competes with live inference packets.
Testing and validation
| Gate | Pass condition |
|---|---|
| Shadow run | New version within 1% of current on a shared frame set |
| Drift alarm | Mean confidence drop past 10% raises a ticket automatically |
Run the rollback drill before you need it. A fleet you cannot revert in minutes is a fleet you will be scared to touch, and a model you are scared to touch is the one that quietly rots.
Related Products




If your fleet runs containers, our explainer on edge orchestration covers the control plane side of these rollouts.
Conclusion
A model lifecycle is not a tool you buy. It is a loop you run: package, deploy to a canary, watch the confidence curve, and keep a rollback one command away. The hardware just has to be stable enough to run that loop untouched for years, which is the reason to start from rugged nodes like the NRU-220 and Nuvo-10208GC rather than a shelf PC. Follow Neteon on LinkedIn for more build guides, contact [email protected], and visit www.neteon.net for datasheets and a model-update pilot scoped to your fleet.
FAQs
What is an AI model lifecycle at the edge?
It is the deploy, monitor, and update loop that keeps a model accurate after it leaves the lab. You version each model as a container, watch its confidence and override rates in production, and push new versions to a canary node before the rest of the fleet.
How do I spot model drift without ground-truth labels in the field?
Track the confidence distribution and the operator override rate, not just the predicted label. A model that keeps choosing the right class at a falling confidence is drifting, and a steady climb in overrides confirms it.
Why run two hardware tiers instead of one?
Heavy multi-camera models need the RTX-class GPU in the Nuvo-10208GC, while lighter detectors run fine on the fanless NRU-220 where power and space are limited. Both pull the same container images, so one build serves the whole fleet.
How do over-the-air model updates avoid breaking a fleet?
Use canary nodes that take new versions first, run them in shadow mode against live frames before they act, and keep a one-command rollback to the previous tag. Updates only roll out fleet-wide after a clean canary week.
Do I need cloud connectivity for this?
No. The model registry, MQTT broker, and dashboards can run on-prem on a host like the Nuvo-11531, so the loop keeps working at sites with intermittent or no internet.
For a factory cell that turns 3D scans into adaptive robot paths, see Nuvo-11531 robotic arm path planning case study.

